The VLA Reality Check: Talk at Nebius Build Berlin
Sergey Arkhangelskiy gave a talk at Nebius Build Berlin titled "The VLA Reality Check: What we learned running models on real robots."
The talk opens with a simple question: is today's robot AI better than yesterday's? Answering it honestly is harder than it sounds. Run model A on Monday and B on Tuesday — most of the difference you measure is the room, not the model. Compare across architectures and you're comparing apples to oranges, because every VLA speaks its own language of inputs, action spaces, and control rates. Pick one metric and you'll miss whether the robot is fast, reliable, or fails gracefully. And ten rollouts on a stochastic system isn't enough to prove anything.
PhAIL is built around the four principles that close those gaps. The slides walk through each one, then show what they tell us about where VLAs are right now.
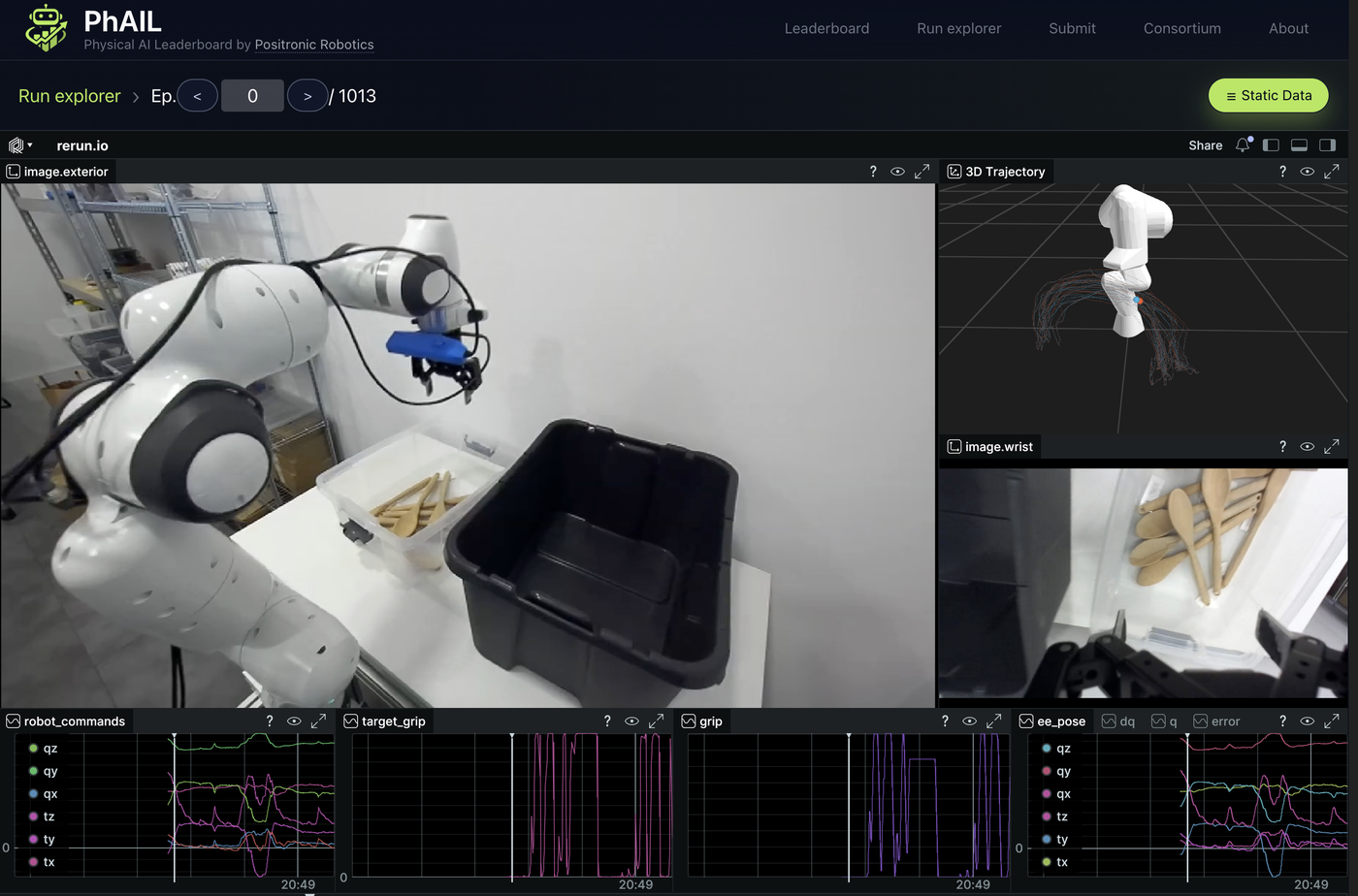
Three numbers from the talk, on four open-source VLAs running on the same rig in April 2026:
- 5% of human throughput from the best model on bin-to-bin picking.
- ~4 minutes mean time between human assists.
- GR00T loses 22 percentage points when the external camera is occluded. OpenPI loses just 6 — robustness is not equal.
The leaderboard is live at phail.ai. Teams that want to fine-tune and submit their own model can talk to us.